Story Behind Facebook Crash - October 2021
Simply appears to be a frivolous joke to us every one of us, we hear - "Facebook is down from web". On 4-5th October 2021 at 15:51 UTC, we opened an inside episode named "Facebook DNS query returning SERVFAIL" on the grounds that we were stressed that something was off-base with our DNS resolver 1.1.1.1. Yet, as we were going to post on our public status page we understood something different more genuine was going on. Online media immediately burst into flares, announcing what our designers quickly affirmed as well. Facebook and its subsidiary administrations WhatsApp and Instagram were, indeed, all down. Their DNS names quit settling, and their framework IPs were inaccessible. Maybe somebody had "pulled the links" from their server farms at the same time and separated them from the Web. This wasn't a DNS issue itself, however bombing DNS was the primary manifestation we'd seen of a bigger Facebook blackout.
Online media immediately burst into blazes, revealing what our designers quickly affirmed as well. Facebook and its partnered administrations WhatsApp and Instagram were, indeed, all down. Their DNS names quit settling, and their framework IPs were inaccessible. Maybe somebody had "pulled the links" from their server farms at the same time and separated them from the Web. This wasn't a DNS issue itself, however bombing DNS was the principal indication we had seen of a bigger Facebook blackout.
What did Facebook say about this issue?
Official Statement: "Our engineering teams have learned that configuration changes on the backbone routers that coordinate network traffic between our data centers caused issues that interrupted this communication. This disruption to network traffic had a cascading effect on the way our data centers communicate, bringing our services to a halt."
Facebook has now published a blog post giving some details of what happened internally. Externally, Cloudfare saw the BGP and DNS problems outlined in this post but the problem actually began with a configuration change that affected the entire internal backbone. That cascaded into Facebook and other properties disappearing and staff internal to Facebook having difficulty getting service going again. Facebook posted a further blog post with a lot more detail about what happened. You can read that post for the inside view and this post for the outside view.
BGP Issue
BGP conventions profits a component to trade steering data between Independent Frameworks Autonomous Systems (AS) on the Web. The large switches that make the Web work have colossal, continually refreshed arrangements of the potential courses that can be utilized to convey each organization parcel to their last objections. Without BGP, the Web switches wouldn't realize what to do, and the Web wouldn't work.
The individual networks each have an ASN: an Autonomous System Number. An Autonomous System (AS) is an individual network with a unified internal routing policy. An AS can begin prefixes (say that they control a gathering of IP addresses), just as travel prefixes (say they realize how to arrive at explicit gatherings of IP addresses). Cloudflare's ASN is AS13335. Each ASN needs to declare its prefix courses to the Web utilizing BGP; any other way, nobody will realize how to associate and where to discover us.
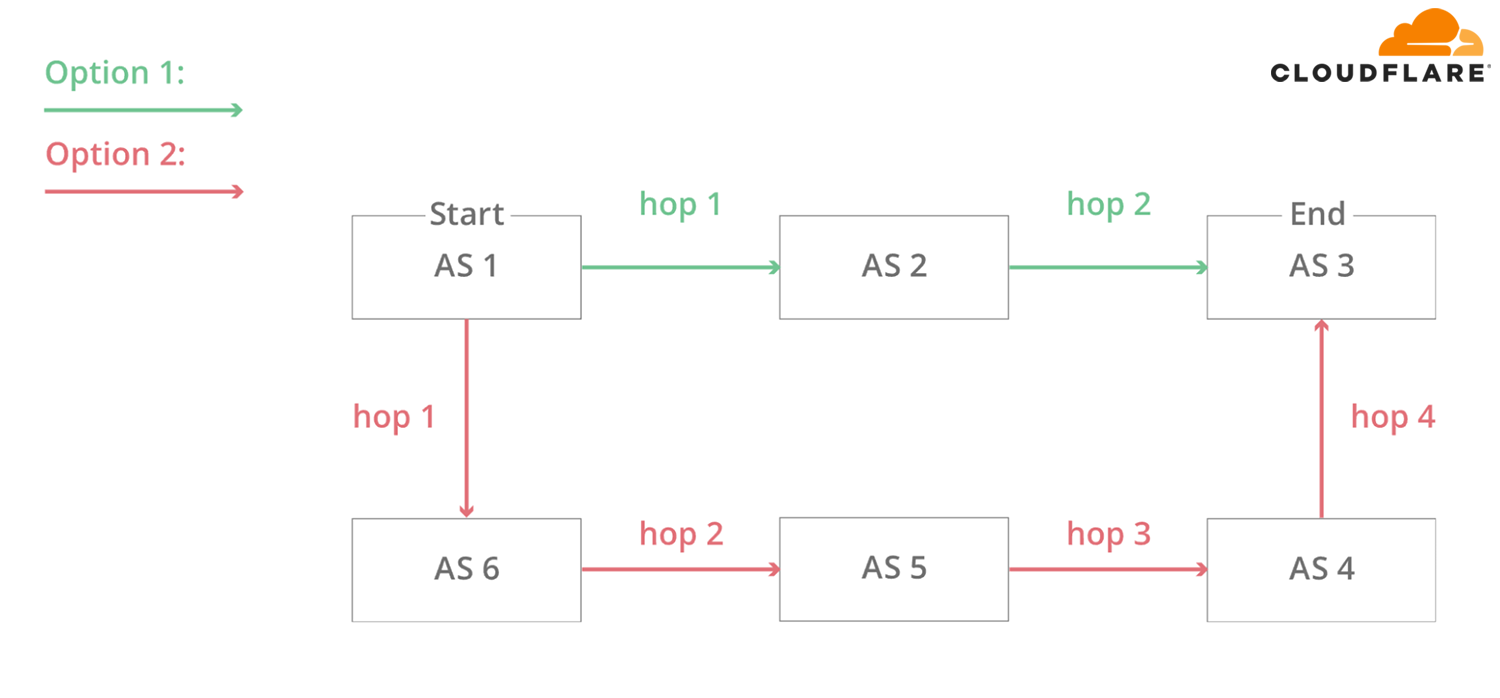
In the above diagram, 6 autonomous systems on the Internet and two possible routes that one packet can use to go from Start to End. AS1 → AS2 → AS3 being the fastest, and AS1 → AS6 → AS5 → AS4 → AS3 being the slowest, but that can be used if the first fails.
At 15:58 UTC, Cloudfare saw that Facebook had quit declaring the courses to their DNS prefixes. That implied that, in any event, Facebook's DNS servers were inaccessible. As a result of this current Cloudflare's 1.1.1.1 DNS resolver could presently don't react to inquiries requesting the IP address of facebook.com.

DNS Cascade
As a direct consequence of this, DNS resolvers all over the world stopped resolving their domain names. One of the systems check done by Couldfare engineers was as follows:
Impact on other services
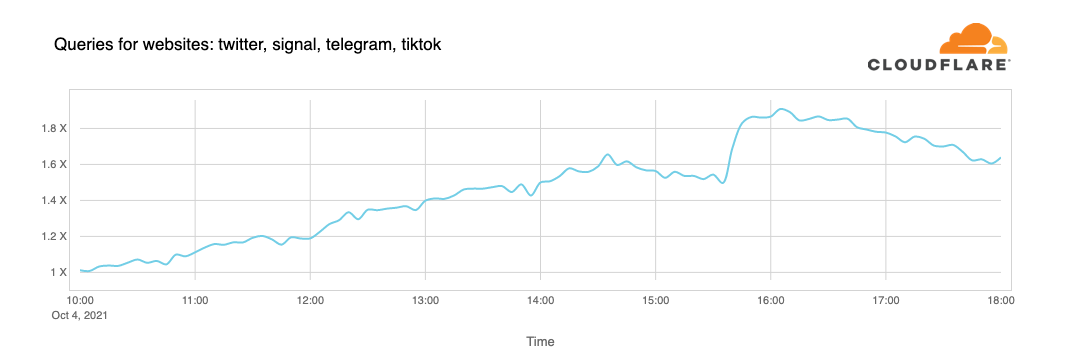
People seek alternatives and want to learn more about or debate what is going on. When Facebook went down, we saw a spike in DNS requests to Twitter, Signal, and other messaging and social media services. The graph below depicts the progressive rise in interaction activity on several social media platforms:
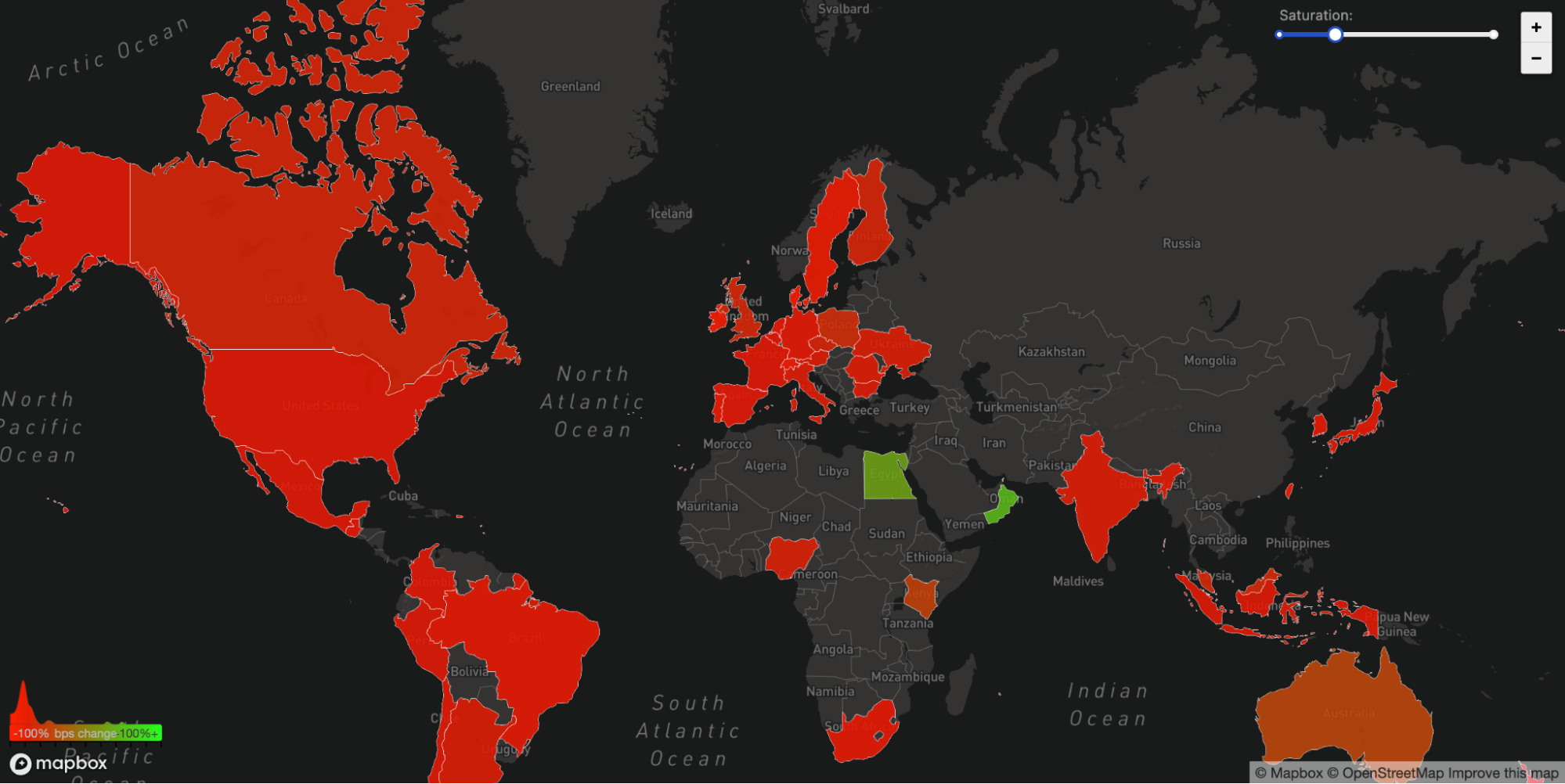
Another side effect of this unavailability may be seen in our WARP traffic to and from Facebook's impacted ASN 32934. This graph depicts how traffic in each nation changed from 15:45 UTC to 16:45 UTC compared to three hours earlier. WARP communications to and from Facebook's network just vanished throughout the world.
Update from Facebook after reboot
At around 21:00 UTC Cloudfare saw renewed BGP activity from Facebook's network which peaked at 21:17 UTC.
PS: These incidents serve as a gentle reminder that the Internet is a very complex and interdependent system comprised of millions of interconnected systems and protocols. That trust, uniformity, and collaboration across entities is at the heart of making it function for almost five billion active users globally.